MINE
Towards Continuous Depth MPI with NeRF for Novel View Synthesis
ICCV 2021
1ByteDance 2National University of Singapore
*Denotes equal contribution



























Abstract and Method
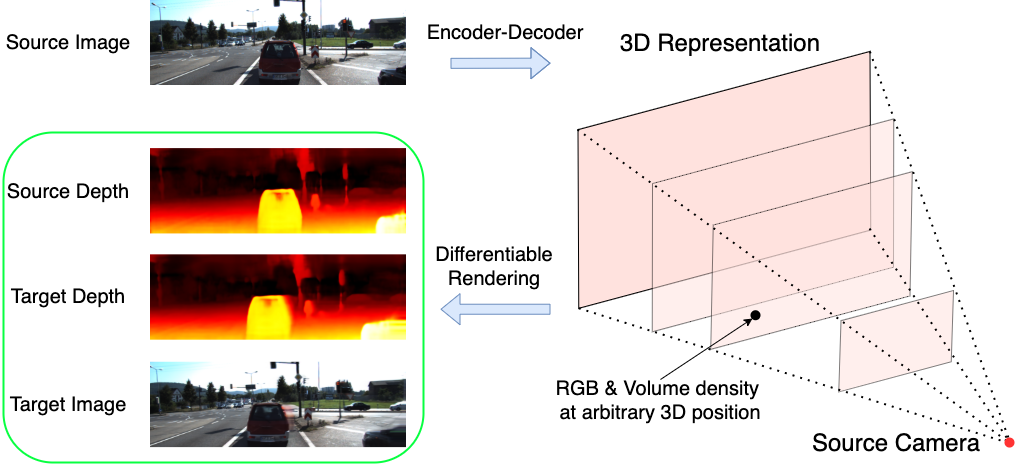
We propose MINE, an approach to perform novel view synthesis and depth estimation via dense 3D reconstruction from a single image.
MINE is a continuous-depth generalization of Multiplane Images (MPI) by introducing the NEural radiance fields.
Given a single image as input, our method predicts a 4-channel image (RGB and volume density) at arbitrary depth values to jointly reconstruct the camera frustum and fill in occluded contents.
The reconstructed and inpainted frustum can then be easily rendered into any novel RGB or depth views using differentiable rendering.
Our network is an encoder-decoder architecture that takes a single image and a list of continuous depth values as inputs and outputs the reconstructed source camera frustum. MINE reconstructs the camera frustum per plane. Our encoder is a fully convolutional network that takes a single image as input and outputs the feature maps. The depth decoder takes this feature maps and a continuous depth value as inputs, and outputs an 4-channel image of RGB values and volume density.
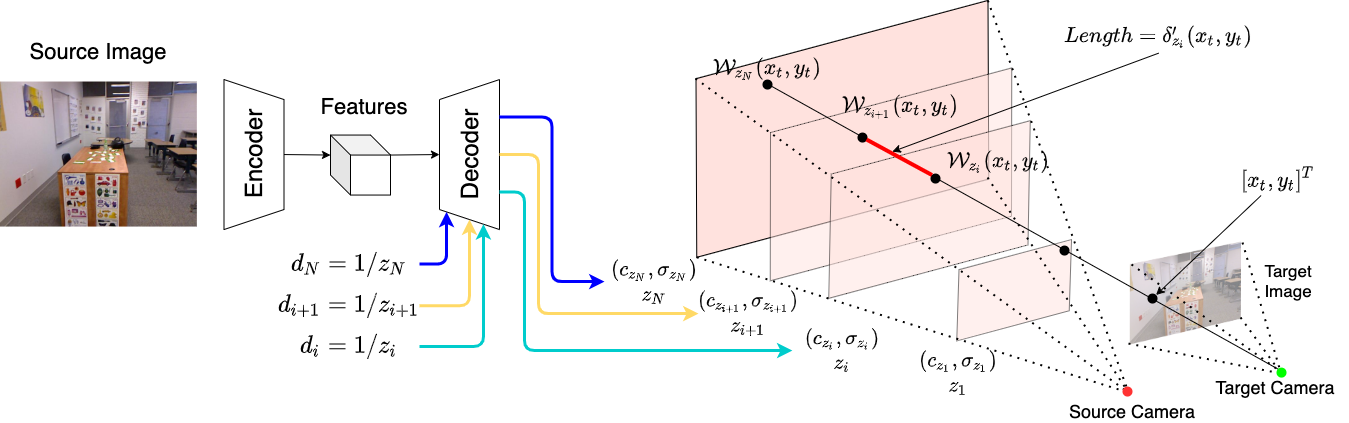
With the reconstructed frustum of the source camera, rendering any novel view only requires an additional homography wrapping step. Imagine a ray that starts from target camera origin and intersects the target image at any pixel coordinate. This ray intersects with the predicted planes in the source camera's frustum, the RGB and volume density is then obtained with bilinear interpolation. The novel view can then be rendered with volume rendering, similar to [Mildenhall et al. 2020].
Related Links
- NeRF was proposed by Mildenhall et al. (2020)
- Single-view novel view synthesis with Multiplane Images by Tucker et al. (2020)
- pixelNeRF and GRF which try to generalize NeRF to unseen scenes
Citation
Acknowledgements
We thank Richard Tucker for helpful discussions. This website is inspired by the template of Michaël Gharbi.